Sampling Distributions
Aleksandr Michuda
Agenda
- Selecting a Sample
- Point Estimation
- Introduction to Sampling Distributions
- Sampling Distribution of \(\bar{x}\).
- Sampling Distribution of \(\bar{p}\).
- Properties of Point Estimators
- Other Sampling Methods
Introduction
- A population is a collection of all the elements of interest.
- A sample is a subset of the population.
Introduction
- The reason we select a sample is to collect data to answer a research question about a population.
- The sample results provide only estimates of the values of the population characteristics.
- The reason is simply that the sample contains only a portion of the population.
- With proper sampling methods, the sample results can provide “good” estimates of the population characteristics.
Sampling from Finite Populations
- A simple random sample of size n from a finite population of size N is a sample selected such that each possible sample of size N has the same probability of being selected.
- Replacing each sampled element before selecting subsequent elements is called sampling with replacement. An element can appear in the sample more than once.
- Sampling without replacement is the procedure used most often.
- In large sampling projects, computer-generated random numbers are often used to automate the sample selection process.
Sampling from a Finite Population
St. Andrew’s College received 900 applications for admission in the upcoming year from prospective students. The applicants were numbered, from 1 to 900, as their applications arrived. The Director of Admissions would like to select a simple random sample of 30 applicants.
- Step 1: Assign a random number to each of the 900 applicants.
- Step 2: Select the 30 applicants corresponding to the 30 smallest random numbers.
Sampling from an INFINITE Population
- Most of the time though, the population is infinite and that’s where the challenge comes in.
- A random selection procedure like above is not sufficient.
- Populations are often generated by an ongoing process; there’s no upper limit on the number of units.
- Some examples of ongoing processes with infinite populations are: - parts being manufactured on a production line - transactions occurring at a bank - telephone calls arriving at a technical help desk - customers entering a store
Sampling from an INFINITE Population
- In the case of an infinite population, we must select a random sample in order to make valid statistical inferences about the population from which the sample is taken.
- A random sample from an infinite population is a sample selected such that the following conditions are satisfied. - Each element selected comes from the population of interest. - Each element is selected independently.
Point Estimation
Point estimation is a form of statistical inference.
In point estimation we use the data from the sample to compute a value of a sample statistic that serves as an estimate of a population parameter.
The sample mean and sample standard deviations are all point estimates of the population mean and population standard deviation.
Example
St. Andrew’s College received 900 applications from prospective students. The application form contains a variety of information including the individual’s Scholastic Aptitude Test (SAT) score and whether or not the individual desires on-campus housing.
At a meeting in a few hours, the Director of Admissions would like to announce the average SAT score and the proportion of applicants that want to live on campus, for the population of 900 applicants.
The data on the applicants have not yet been entered in the college’s database. So the Director decides to estimate the values of the population parameters of interest based on sample statistics. A sample of 30 applicants is selected using computer-generated random numbers.
Example
- \(\bar{x}\) is the point estimator of the population mean, \(\mu\)
\[ \bar{x}=\frac{\sum x_i}{n}=\frac{50,520}{30}=1684 \]
- \(s\) is the point estimator of the population standard deviation, \(\sigma\)
\[ s=\sqrt{\frac{\sum\left(x_i-\bar{x}\right)^2}{n-1}}=\sqrt{\frac{2470.8}{29}}=85.2 \]
- \(\bar{p}\) is the point estimator of the population proportion, \(p\).
\[ \bar{p}=20 / 30=.67 \]
Note: Different random numbers would have identified a different sample which would have resulted in different point estimates.
Example
If we were to collect the data from all 900 applicants, we would have the following population parameters:

The Sample Mean as a Point Estimator
- The sample mean, \(\bar{x}\), is a point estimator of the population mean, \(\mu\).
- But since it is based on a sample, it is subject to sampling variability.
- The sample mean is then a random variable.
- If we were to take many random samples of the same size from the same population, the sample means would vary from sample to sample.
- But on average, or in expectation, it SHOULD be equal to the population mean
Sampling Distribution of \(\bar{x}\)
- This means what?
- \(E(\bar{x}) = ?\)
Sampling Distribution of \(\bar{x}\)
- If the expected value of our point estimate equals the population parameter, then we say that the point estimate is unbiased.
Sampling Distribution of \(\bar{x}\)
- When the population has a normal distribution, the sampling distribution of \(\bar{x}\) is normally distributed for any sample size.
- In most applications, the sampling distribution of \(\bar{x}\) can be approximated by a normal distribution whenever the sample is size 30 or more.
- This is a bit of voodoo…
- Why n=30?
The Central Limit Theorem
- We can see that with a normally distributed population, the sample mean is a good estimator of the population mean.
- But what if the population is not normally distributed?
- It’s okay, because of the Central Limit Theorem.
Central Limit Theorem
If we have a random sample of size n from a population with mean \(\mu\) and standard deviation \(\sigma\), then the sampling distribution of \(\bar{x}\) will be approximately normally distributed for large \(n\).
The Central Limit Theorem
- What the Central Limit Theorem tells us is that for a large enough sample size, it doesn’t matter what the population distribution is
- The sample average can be treated as being normally distributed.
The Central Limit Theorem
The Central Limit Theorem tells us that for any random variable, \(x\), its sample mean \(\bar{x}\) will be normally distributed for large enough sample sizes.
Specifically for a “large enough” sample size, \(\bar{x}\) will be normally distributed with mean \(\mu\) and standard deviation \(\sigma/\sqrt{n}\)
So \(\bar{x} \sim N(\mu, \sigma/\sqrt{n})\).
The Difference between \(x\) and \(\bar{x}\)
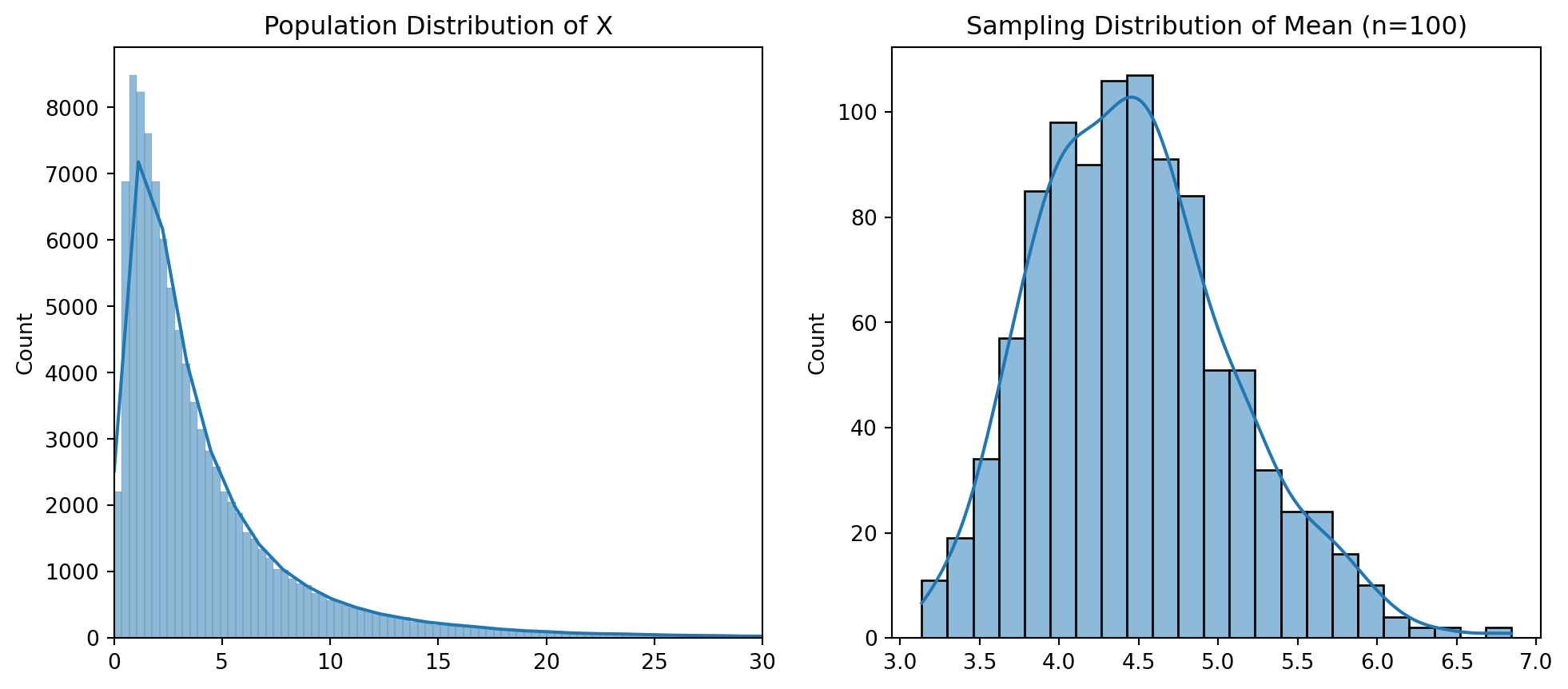
- Let’s say that we have a population of 100,000 that is distributed with a skew.
- We can check this by continually taking samples from the population and plotting the distribution of the samples.
Let’s take random samples of 100 observations, 1,000 times and plot the distribution of \(\bar{x}\).
Other Sampling Methods
- Stratified Random Sampling
- Cluster Sampling
- Systematic Sampling
- Convenience Sampling
- Judgment Sampling
Stratified Random Sampling
- The population is first divided into groups of elements called strata.
- Each element in the population belongs to one and only one stratum.
- Best results are obtained when the elements within each stratum are as much alike as possible (i.e. a homogeneous group).
Stratified Random Sampling
- A simple random sample is taken from each stratum.
- Formulas are available for combining the stratum sample results into one population parameter estimate.
- Advantage: If strata are homogeneous, this method provides results that is as “precise” as simple random sampling but with a smaller total sample size.
- Example: The basis for forming the strata might be department, location, age, industry type, and so on.
Cluster Sampling
- The population is first divided into separate groups of elements called clusters.
- Ideally, each cluster is a representative small-scale version of the population (i.e. heterogeneous group).
- A simple random sample of the clusters is then taken.
- All elements within each sampled (chosen) cluster form the sample.
Cluster Sampling
- Example: A primary application is area sampling, where clusters are city blocks or other well-defined areas.
- Advantage: The close proximity of elements can be cost effective (i.e. many sample observations can be obtained in a short time).
- Disadvantage: This method generally requires a larger total sample size than simple or stratified random sampling.
Difference between Clusters and Strata
- In stratified sampling, the population is divided into strata and a simple random sample is taken from each stratum.
- In cluster sampling, the population is divided into clusters and a simple random sample of the clusters is taken.
- So for stratification, you are still picking individual units within the strata
- But clustering, you are just randomly selecting the clusters and then taking all the units within the cluster.
Systematic Sampling
- If a sample size of n is desired from a population containing N elements, we might sample one element for every N/n elements in the population.
- We randomly select one of the first N/n elements from the population list.
- We then select every N/nth element that follows in the population list.
Systematic Sampling
- This method has the properties of a simple random sample, especially if the list of the population elements is a random ordering.
- Advantage: The sample usually will be easier to identify than it would be if simple random sampling were used.
- Example: Selecting every 100th listing in a telephone book after the first randomly selected listing.
Convenience Sampling
- It is a nonprobability sampling technique. Items are included in the sample without known probabilities of being selected.
- The sample is identified primarily by convenience.
- Example: A professor conducting research might use student volunteers to constitute a sample.
- Advantage: Sample selection and data collection are relatively easy.
- Disadvantage: It is impossible to determine how representative of the population the sample is.
Judgment Sampling
- The person most knowledgeable on the subject of the study selects elements of the population that he or she feels are most representative of the population.
- It is a nonprobability sampling technique.
- Example: A reporter might sample three or four senators, judging them as reflecting the general opinion of the senate.
- Advantage: It is a relatively easy way of selecting a sample.
- Disadvantage: The quality of the sample results depends on the judgment of the person selecting the sample.
Recommendation
- It is recommended that probability sampling methods (simple random, stratified, cluster, or systematic) be used.
- For these methods, formulas are available for evaluating the “goodness” of the sample results in terms of the closeness of the results to the population parameters being estimated.
- An evaluation of the goodness cannot be made with non-probability (convenience or judgment) sampling methods.
When would you use each method in practice?
Simple random sampling
U.S. National Health and Nutrition Examination Survey (NHANES) uses simple random sampling to select participants.
Their goal is to be representative of the U.S. population, so they make sure to give everyone an equal chance of being selected.
Stratified random sampling
Sometimes you are interested in a specific subgroup of the population, even if it might be smaller than the majority.
The Census stratifies based on geographic location to make sure that areas with less populated regions are not underrepresented in the sample
Cluster random sampling
The National Immunization Survey conducted by the CDC is done through cluster random sampling.
Geographic areas are put into clusters by county or zip code and those zip-codes are sampled.
Note
Why might this be a good idea when it comes to immunization, vaccines or disease prevalence?
Code
points = Array.from({ length: 100 }, (_, i) => ({
x: (i % 10) / 10,
y: Math.floor(i / 10) / 10,
group: i % 10 < 5 ?
(Math.floor(i / 10) < 5 ? 'red' : 'blue') :
(Math.floor(i / 10) < 5 ? 'green' : 'orange'),
opacity: 1
}));
// Sampling method selection
viewof samplingMethod = Inputs.select(
['simple random sample', 'stratified random sample', 'cluster random sample', 'systematic random sample'],
{ label: "Sampling Method" }
)
// Sampling functions
function simpleRandomSample() {
const sampledIndices = d3.shuffle([...Array(points.length).keys()]).slice(0, 32);
return points.map((p, i) => ({
...p,
opacity: sampledIndices.includes(i) ? 1 : 0.1
}));
}
function stratifiedRandomSample() {
const byGroup = d3.group(points, d => d.group);
const sampledPoints = [];
byGroup.forEach(groupPoints => {
const sampledIndices = d3.shuffle([...Array(groupPoints.length).keys()]).slice(0, 8);
sampledIndices.forEach(index => {
sampledPoints.push(groupPoints[index]);
});
});
return points.map(p => ({
...p,
opacity: sampledPoints.includes(p) ? 1 : 0.1
}));
}
function clusterRandomSample() {
const selectedGroups = d3.shuffle(['red', 'blue', 'green', 'orange']).slice(0, 2);
return points.map(p => ({
...p,
opacity: selectedGroups.includes(p.group) ? 1 : 0.1
}));
}
function systematicRandomSample() {
const start = Math.floor(Math.random() * 3);
return points.map((p, i) => ({
...p,
opacity: (i - start) % 3 === 0 ? 1 : 0.1
}));
}
// Apply sampling and plot
sampledPoints = {
let method = samplingMethod;
switch(method) {
case 'simple random sample':
return simpleRandomSample();
case 'stratified random sample':
return stratifiedRandomSample();
case 'cluster random sample':
return clusterRandomSample();
case 'systematic random sample':
return systematicRandomSample();
default:
throw new Error(`Unknown sampling method: ${method}`);
}
}
Plot.plot({
width: 400,
height: 400,
marks: [
Plot.dot(sampledPoints, {
x: "x",
y: "y",
fill: "group",
fillOpacity: "opacity"
})
]
});